跟着王小美和三岁一起学paddle(3)--图像分类
跟王小美与三岁一起学paddle — 图像分类!
简单有趣带你图像分类
跟王小美与三岁一起学paddle 第三讲
致读者
在看这个notebook的你,对没错就是你
关注王小美喵,点个star⭐谢谢喵
注:本项目部分图片为自制,非授权请勿私自使用
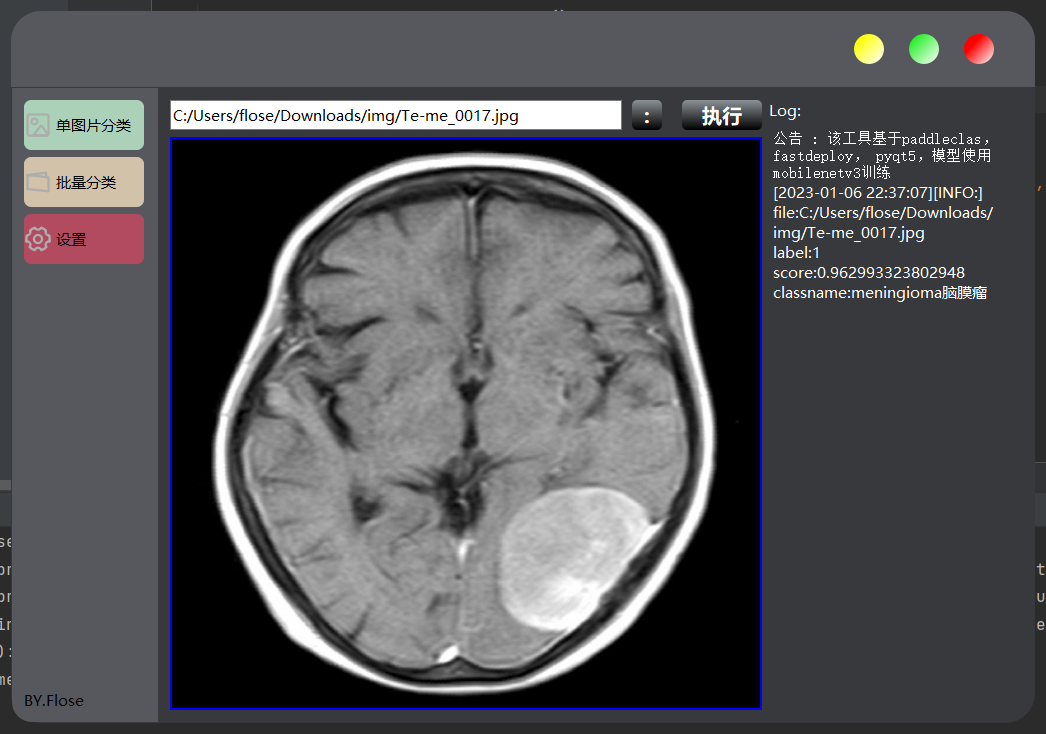
下图是我做的一个小应用,后面有时间会出一期教大家如何从零到完成一个AI应用
| 王小美: |

| 三岁: |
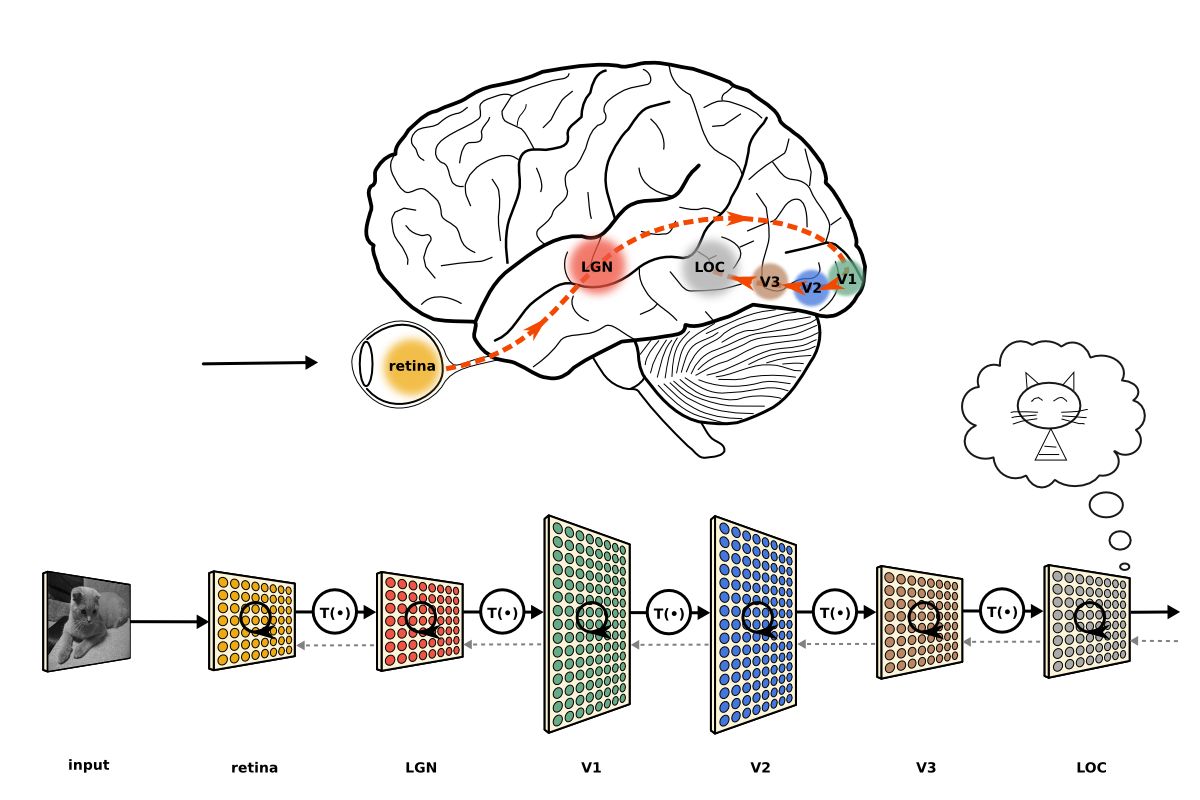
要自瞄首先就要知道物体的位置,这时候就需要目标检测技术,在学习目标检测之前我们先从图像分类开始吧!!!
图像分类
根据各自在图像信息中所反映的不同特征,把不同类别的目标区分开来的图像处理方法
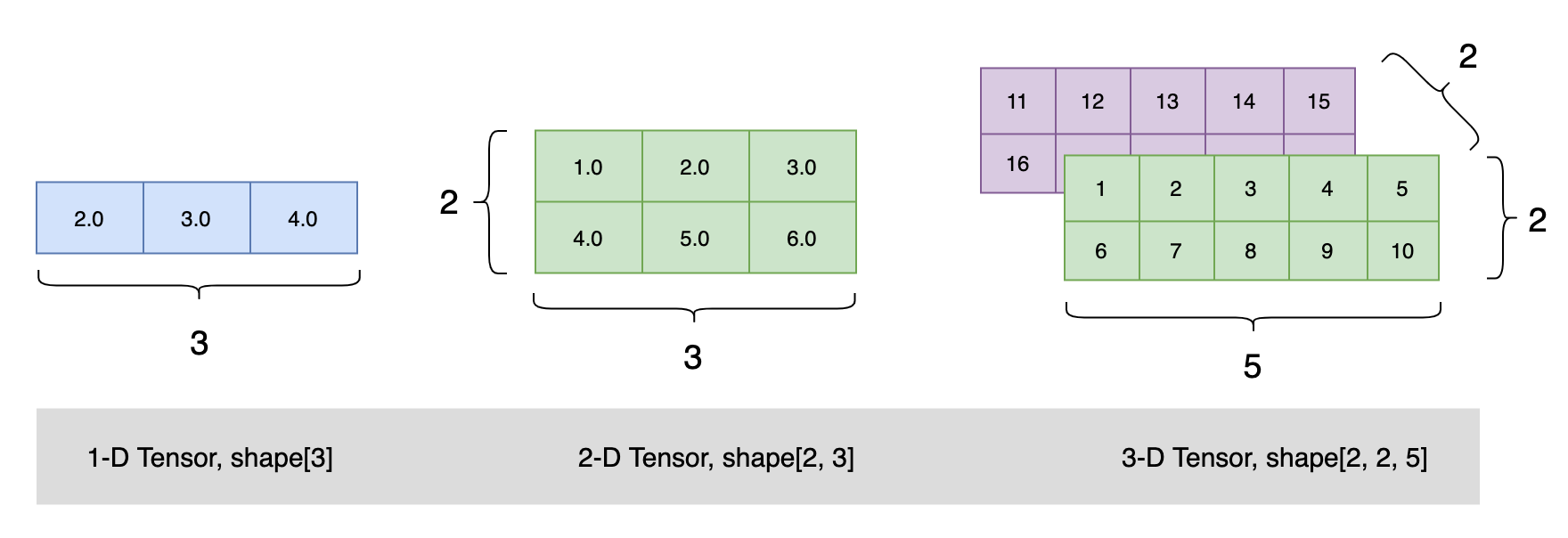
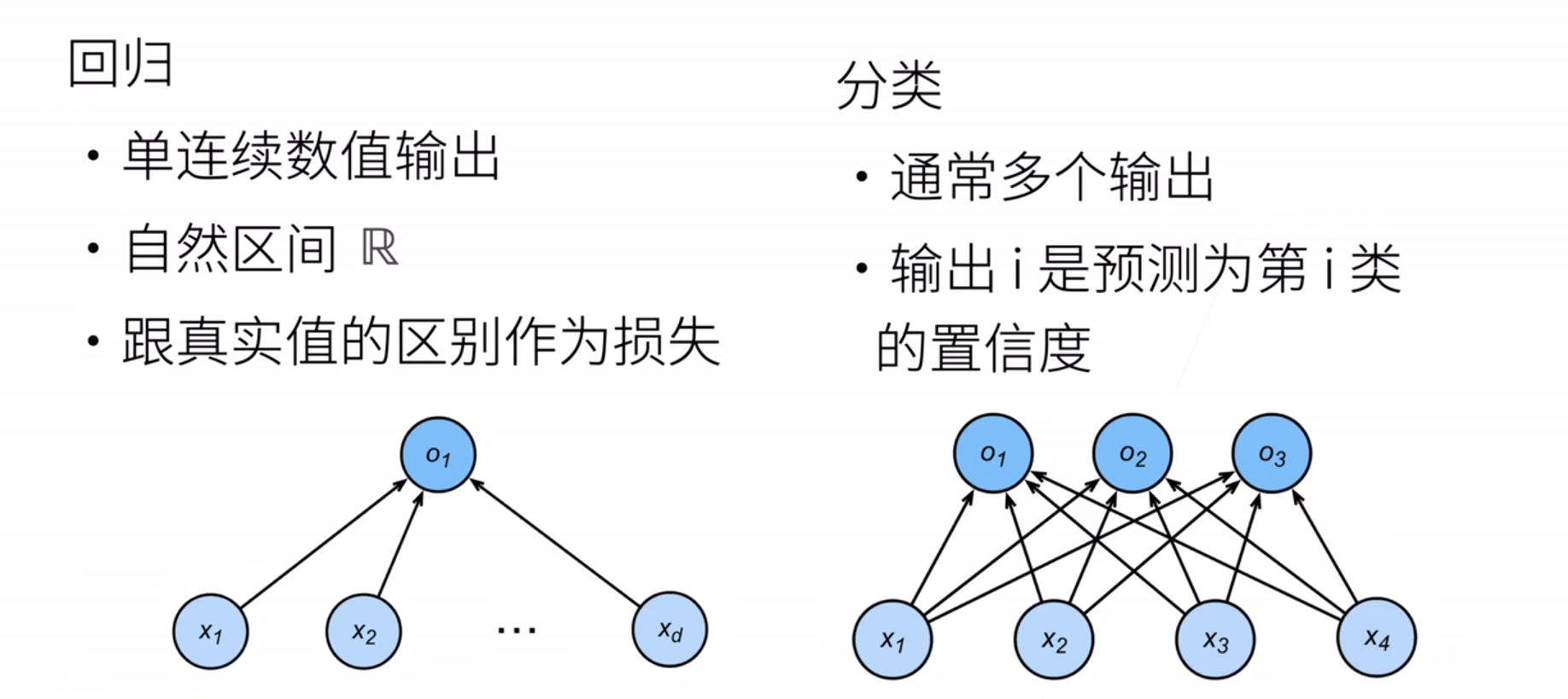
我们从一个图像分类问题开始。 假设每次输入是一个2x2的灰度图像。 我们可以用一个标量表示每个像素值。每个图像有四个特征x1,x2,x3,x4
假设每个图像属于类别“猫”“鸡”和“狗”中的一个。接下来,我们要选择如何表示标签?ヾ(=・ω・=)o
独热编码(one-hot encoding)
独热编码是一个向量,它的分量和类别一样多。 类别对应的分量设置为1,其他所有分量设置为0。
在我们的例子中,标签将是一个三维向量(1,0,0)代表“猫” ,(0,1,0)代表“鸡”,(0,0,1)代表“狗”
| 三岁: |
| 三岁: |
上图中的O我们称之为 未规范化的预测(logit)
| 三岁: |
相信你已经能知道我们是如何通过神经网络来预测分类结果了
我们希望模型的输出Yj可以视为属于类j的概率, 然后选择具有最大输出值的类别作为我们的预测。
例如,如果Y1、Y2、Y3分别为0.1、0.8和0.1, 那么我们预测的类别是2,在我们的例子中代表“鸡”。
但是我们通过上面的网络输出的Oj并不是像Yj这样和为1的正数,我们要如何对Oj进行处理呢?接下来就要用到softmax函数了
SoftMax函数
softmax函数能够将未规范化的预测变换为非负数并且总和为1,同时让模型保持 可导的性质。
为了完成这一目标,我们首先对每个未规范化的预测求幂,这样可以确保输出非负。
为了确保最终输出的概率值总和为1,我们再让每个求幂后的结果除以它们的总和
softmax运算不会改变未规范化的预测之间的大小次序,只会确定分配给每个类别的概率
尽管softmax是一个非线性函数,但softmax回归的输出仍然由输入特征决定。 因此,softmax回归是一个线性模型
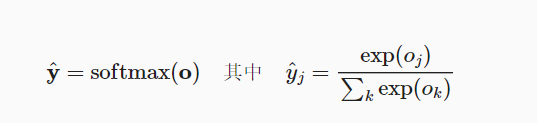
| 王小美: |
其实这里面就涉及到许多数学上的内容了
三岁: 其实我们使用softmax函数处理的话可以让我们输出的大部分值处在一个范围区间
在我们生活中,热水器的控温是不是没有在0到100度之间,而是在一个人体感受良好的范围内,这是不是就利于我们调节了
softmax函数其中就具有这个思想
| 三岁: |
交叉熵(cross-entropy loss)
交叉熵(Cross Entropy)是Shannon信息论中一个重要概念
它是分类问题最常用的损失之一
这边借用李沐大佬的图

| 王小美: |
| 三岁: |
竟然你诚心诚意的发问了,那我就大发慈悲的告诉你把!
要明白交叉熵首先要知道什么是熵
信息熵
信息熵也被称为熵,用来表示所有信息量的期望。
期望是试验中每次可能结果的概率乘以其结果的总和。
所以信息量的熵可表示为:
例如
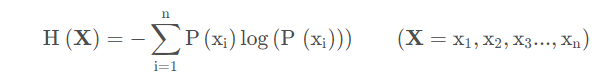

| 三岁: |
明白了熵的概念后,我们再来看一下什么是KL散度
KL散度
如果对于同一个随机变量X有两个单独的概率分布P(x)和Q(x),则我们可以使用KL散度来衡量这两个概率分布之间的差异。
在我们的例子中,标签将是一个三维向量(1,0,0)代表“猫” ,(0,1,0)代表“鸡”,(0,0,1)代表“狗”
如果我们预测一张图像是猫的真实分布P(X)是(1,0,0) softmax函数输出是预测分布Q(X) = (0.7,0.2,0.1)
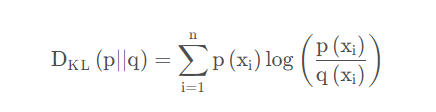
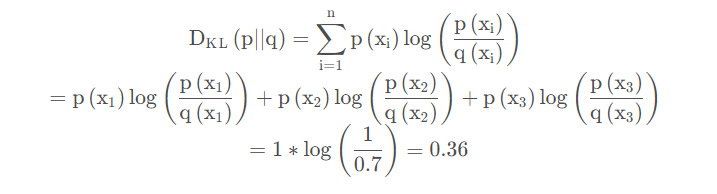
| 三岁: |
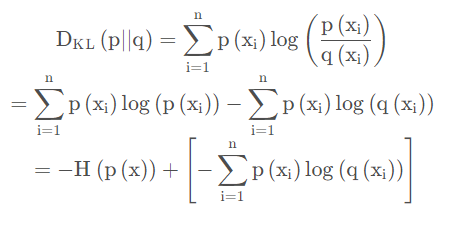
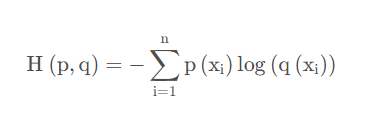
| 王小美: |
原来是这样啊,我懂了!(p≧w≦q)
小结
softmax运算可以把网络输出结果转换成概率
softmax回归适用于分类问题,它使用了softmax运算中输出类别的概率分布。
交叉熵是一个衡量两个概率分布之间差异的很好的度量,它测量给定模型编码数据所需的比特数。
| 三岁: |
让我们来通过paddle的api快速对Mnist数据集实现softmax回归吧!ヾ(=・ω・=)o
Mnist数据集是一个手写数字数据集哦!

SoftMax回归的代码实现(基于paddle2.0)
| 三岁: |
还记得我说的步骤吗?
1.数据处理
2.网络搭建
3.模型训练和调参
4.模型推理
5.模型部署
1.数据处理
paddle数据集函数介绍
paddle.vision.datasets.MNIST
MNIST 数据集的实现。
参数
image_path (str,可选) - 图像文件路径,如果 download 参数设置为 True,image_path 参数可以设置为 None。默认值为 None,默认存放在:~/.cache/paddle/dataset/mnist。
label_path (str,可选) - 标签文件路径,如果 download 参数设置为 True,label_path 参数可以设置为 None。默认值为 None,默认存放在:~/.cache/paddle/dataset/mnist。
mode (str,可选) - ‘train’ 或 ‘test’ 模式两者之一,默认值为 ‘train’。
transform (Callable,可选) - 图片数据的预处理,若为 None 即为不做预处理。默认值为 None。
download (bool,可选) - 当 data_file 是 None 时,该参数决定是否自动下载数据集文件。默认值为 True。
backend (str,可选) - 指定要返回的图像类型:PIL.Image 或 numpy.ndarray。必须是 {‘pil’,’cv2’} 中的值。如果未设置此选项,将从 paddle.vision.get_image_backend 获得这个值。默认值为 None。
1 | import paddle |
item 26/2421 [..............................] - ETA: 5s - 2ms/item
Cache file /home/aistudio/.cache/paddle/dataset/mnist/train-images-idx3-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/mnist/train-images-idx3-ubyte.gz
Begin to download
item 8/8 [============================>.] - ETA: 0s - 3ms/item
Download finished
Cache file /home/aistudio/.cache/paddle/dataset/mnist/train-labels-idx1-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/mnist/train-labels-idx1-ubyte.gz
Begin to download
Download finished
item 67/403 [===>..........................] - ETA: 0s - 2ms/item
Cache file /home/aistudio/.cache/paddle/dataset/mnist/t10k-images-idx3-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/mnist/t10k-images-idx3-ubyte.gz
Begin to download
item 2/2 [===========================>..] - ETA: 0s - 2ms/item
Download finished
Cache file /home/aistudio/.cache/paddle/dataset/mnist/t10k-labels-idx1-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/mnist/t10k-labels-idx1-ubyte.gz
Begin to download
Download finished
2.网络搭建
组网函数介绍
paddle.nn.Sequential
顺序容器。子 Layer 将按构造函数参数的顺序添加到此容器中。传递给构造函数的参数可以 Layers 或可迭代的 name Layer 元组。
softmax回归的输出层是一个全连接层。因此,为了实现我们的模型,我们只需在Sequential中添加一个带有10个输出的全连接层
paddle.nn.Flatten
构造一个 Flatten 类的可调用对象。它实现将一个连续维度的 Tensor 展平成一维 Tensor。
参数
start_axis (int,可选) - 展开的起始维度,默认值为 1。
stop_axis (int,可选) - 展开的结束维度,默认值为-1。
paddle.nn.ReLU
ReLU 激活层(Rectified Linear Unit)。计算公式如下:
ReLU(x)=max(0,x)
paddle.nn.Dropout
Dropout 是一种正则化手段,该算子根据给定的丢弃概率 p,在训练过程中随机将一些神经元输出设置为 0,通过阻止神经元节点间的相关性来减少过拟合。
1 | Net = paddle.nn.Sequential( |
3.模型训练
使用 paddle.Model 封装模型
Model 对象是一个具备训练、测试、推理的神经网络。该对象同时支持静态图和动态图模式,通过 paddle.disable_static() 来切换。需要注意的是,该开关需要在实例化 Model 对象之前使用。输入需要使用 paddle.static.InputSpec 来定义。
使用高层 API 训练模型前,可使用 paddle.Model 将模型封装为一个实例,方便后续进行训练、评估与推理。
使用 Model.prepare 配置训练准备参数
用 paddle.Model 完成模型的封装后,需通过 Model.prepare 进行训练前的配置准备工作,包括设置优化算法、Loss 计算方法、评价指标计算方法:
优化器(optimizer):即寻找最优解的方法,可计算和更新梯度,并根据梯度更新模型参数。飞桨框架在 paddle.optimizer 下提供了优化器相关 API。并且需要为优化器设置合适的学习率,或者指定合适的学习率策略,飞桨框架在 paddle.optimizer.lr 下提供了学习率策略相关的 API。
损失函数(loss):用于评估模型的预测值和真实值的差距,模型训练过程即取得尽可能小的 loss 的过程。飞桨框架在 paddle.nn Loss层 提供了适用不同深度学习任务的损失函数相关 API。
评价指标(metrics):用于评估模型的好坏,不同的任务通常有不同的评价指标。飞桨框架在 paddle.metric 下提供了评价指标相关 API。
使用 Model.fit 训练模型
做好模型训练的前期准备工作后,调用 Model.fit 接口来启动训练。 训练过程采用二层循环嵌套方式:内层循环完成整个数据集的一次遍历,采用分批次方式;外层循环根据设置的训练轮次完成数据集的多次遍历。因此需要指定至少三个关键参数:训练数据集,训练轮次和每批次大小:
训练数据集:传入之前定义好的训练数据集。
训练轮次(epoch):训练时遍历数据集的次数,即外循环轮次。
批次大小(batch_size):内循环中每个批次的训练样本数。
除此之外,还可以设置样本乱序(shuffle)、丢弃不完整的批次样本(drop_last)、同步/异步读取数据(num_workers) 等参数,另外可通过 Callback 参数传入
回调函数,在模型训练的各个阶段进行一些自定义操作,比如收集训练过程中的一些数据和参数
1 | # 预计模型结构生成模型实例,便于进行后续的配置、训练和验证 |
The loss value printed in the log is the current step, and the metric is the average value of previous steps.
Epoch 1/5
step 938/938 [==============================] - loss: 0.1564 - acc: 0.9289 - 15ms/step
Epoch 2/5
step 938/938 [==============================] - loss: 0.1323 - acc: 0.9687 - 16ms/step
Epoch 3/5
step 938/938 [==============================] - loss: 0.0240 - acc: 0.9779 - 15ms/step
Epoch 4/5
step 938/938 [==============================] - loss: 0.0049 - acc: 0.9826 - 16ms/step
Epoch 5/5
step 938/938 [==============================] - loss: 0.0314 - acc: 0.9862 - 15ms/step
模型验证
通过loss和acc的结果来评断模型训练的质量和效率
1 | model.evaluate(val_dataset, verbose=1) |
Eval begin...
step 10000/10000 [==============================] - loss: 3.5763e-07 - acc: 0.9807 - 2ms/step
Eval samples: 10000
{'loss': [3.5762793e-07], 'acc': 0.9807}
模型保存与加载
模型训练后,训练好的模型参数保存在内存中,通常需要使用模型保存(save)功能将其持久化保存到磁盘文件中,并在后续需要训练调优或推理部署时,再加载(load)到内存中运行。
1 | model.save('/home/aistudio/model/model') # 保存训练完的模型 |
1 | # 加载动态图模型参数和优化器参数 |
The loss value printed in the log is the current step, and the metric is the average value of previous steps.
Epoch 1/2
step 938/938 [==============================] - loss: 0.0352 - acc: 0.9883 - 15ms/step
Epoch 2/2
step 938/938 [==============================] - loss: 0.0105 - acc: 0.9905 - 15ms/step
| 三岁: |
本次图像分类是介绍softmax回归的一个小任务,下次讲卷积神经网络的时候我会再和你一起完成一次哦!
今天就讲到这了,竟然没看睡着,不错嘛(o°ω°o)

| 王小美: |
我懂了,原来图像分类是这样做的ヾ(≧?≦)〃
太棒了!!!
作者简介
ID:Flose
School:浙大宁波理工学院
专业:自动化
宁理炼丹师协会-飞桨领航团QQ群:699816720
深度学习菜狗,正在不断努力,咱们一起加油