跟着王小美和三岁一起学paddle--Tensor是什么?
跟王小美与三岁一起学paddle — 开启新梦想
你是否因为不懂基础知识而感到迷茫呢?
是否因为看不懂网上的视频而苦恼呢?
是否对paddle多种多样的api怎么使用而摆烂呢?
零基础? 不用怕!我和你一样!
今天由小白新手王小美和三岁老师大家一起开启paddle学习新征程!
| 王小美: |

[人物设定]
姓名:王小美
年龄:13岁
身高:155
体重:null
角色性格:充满活力和好奇心的女生,她喜欢探索新的事物,并且对人工智能非常感兴趣。
她性格开朗,喜欢交朋友,并且乐于助人。虽然她有时会因为过于激动而鲁莽,但她的心思总是善良的。
所属社团:宁理炼丹师协会
| 王小美: |
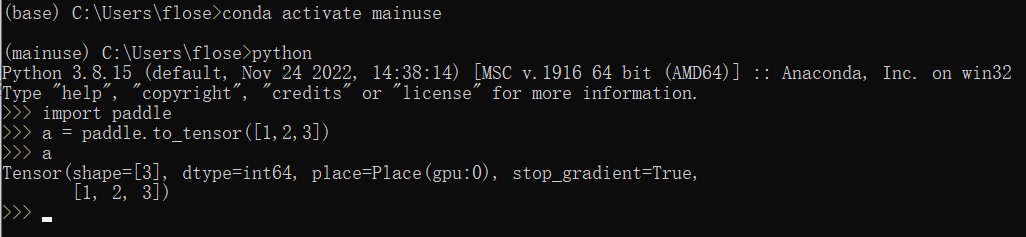
通过三岁老师的本地paddle安装教程我终于把paddle安装好了
| 王小美: |
| 三岁: |
三岁:可以的哦,但是你得先学习基础知识哦,只要努力学习你一定能成为大牛的。先让我们从最基本的Tensor学起吧! (★ᴗ★)
Tensor->张量
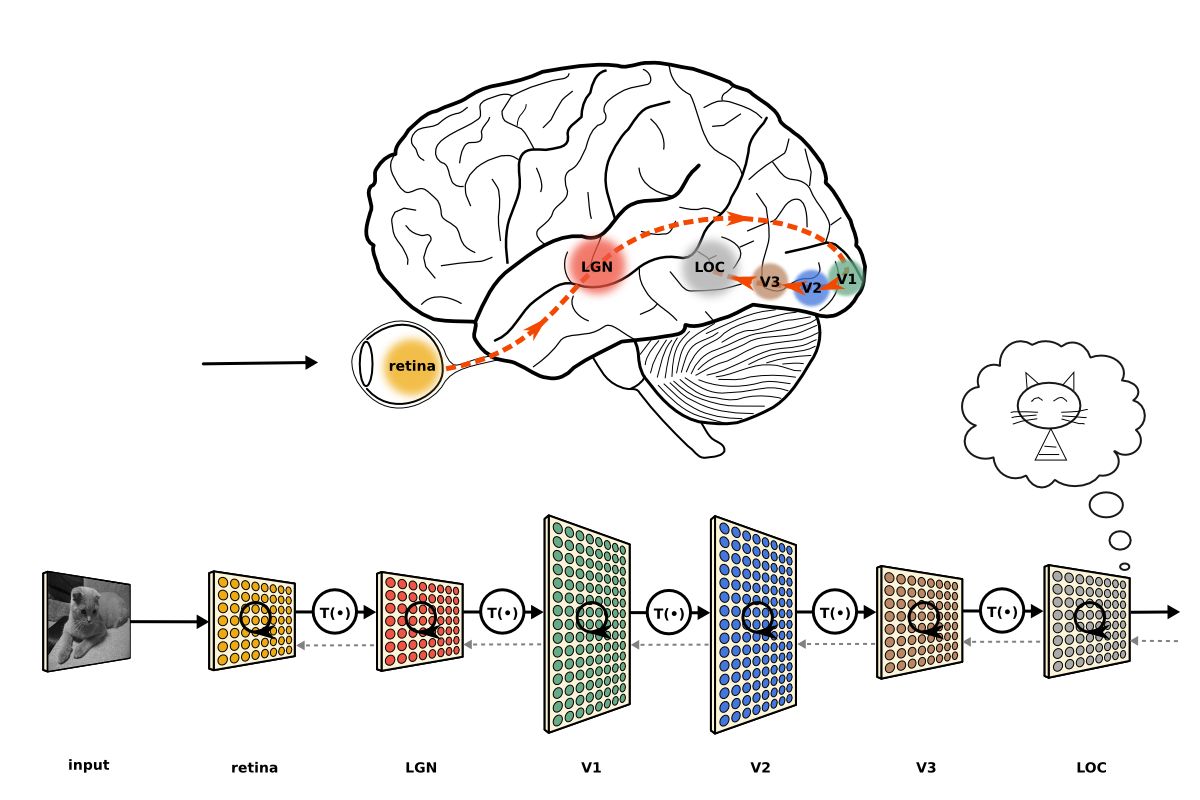
在paddle中和大多数的深度学习框架一样Tensor是运算的基础,那么什么是Tensor呢?让我们一起来看看吧!
这是paddle提供的一种数据结构和python的几种内置结构类型有所不同,他更类似于C语言的多维数组,和Numpy的array相类似
我们可以非常方便的读取到位置上的内容,但是不能够轻易的给已经生成的Tensor添加成员或者生成维度(优缺点)
所有的修改都需要通过新建在把数据处理后复制进去(paddle对此作了一定程度的封装,便于使用)
所谓千言万语不如一张图的信息量大这里我用三岁大佬的一张图来进行概括
眼尖的同学可能已经发现了,王小美同学在检验paddle是否成功安装的时候使用paddle的api生成了一个Tensor并将他打印出来了,让我们用notebook来复现一下吧!
1 | # 首先我们导入paddle包 |
Tensor(shape=[3], dtype=int64, place=Place(cpu), stop_gradient=True,
[1, 2, 3])
| 王小美: |
| 三岁: |
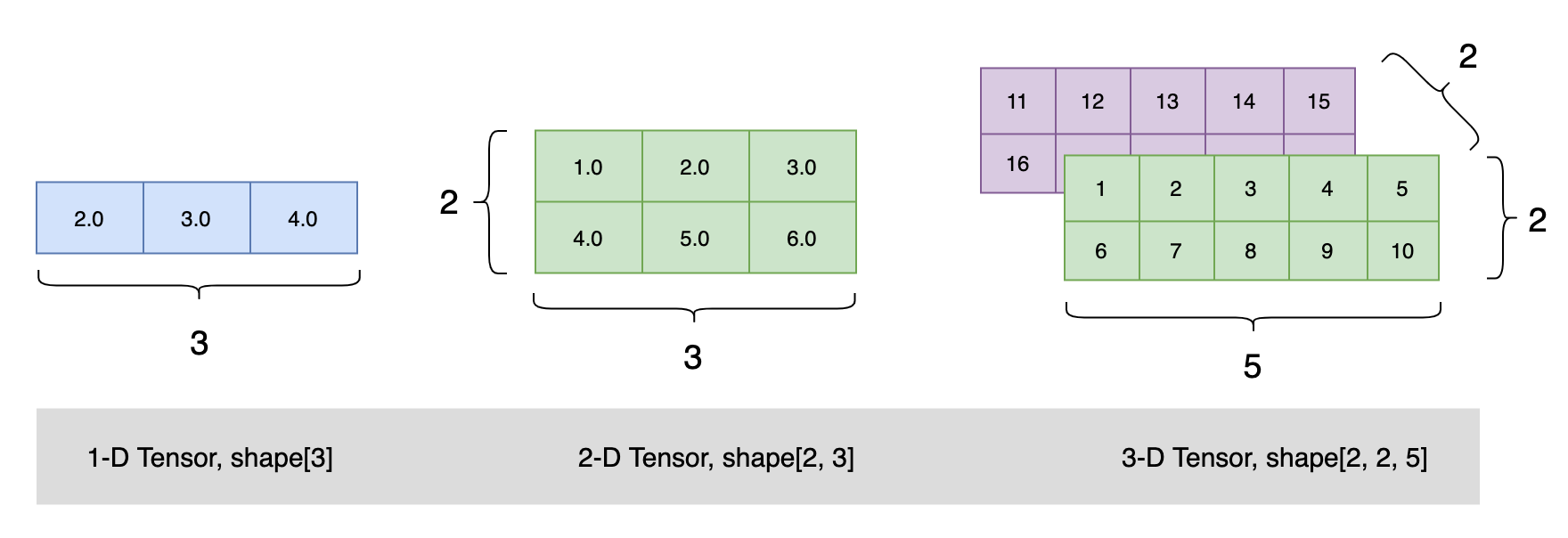
结果解析
shape=[3]:一维长度为3;
dtype=float64:类型是64位的;
place=Place(gpu:0) 使用的是gpu
如果这里是CPUPlace:使用的是cpu;stop_gradient=True:不求导,不参加梯度更新;
[1., 2., 3.]内容是[1., 2., 3.]
| 王小美: |
1 | # 生成一个只有单个整数1的tensor |
只有单个整数1的tensor
Tensor(shape=[1], dtype=int64, place=Place(gpu:0), stop_gradient=True,
[1])
二维的tensor
Tensor(shape=[2, 3], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[1., 2., 3.],
[4., 5., 6.]])
三维的tensor
Tensor(shape=[1, 3, 3], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[[1., 2., 3.],
[1., 2., 3.],
[1., 2., 3.]]])
| 王小美: |
| 三岁: |
| 王小美: |
| 三岁: |
Tensor与Numpy array的相互转换
由于Tensor与Numpy array在表现上极为相似,转换也便存在可能
使用Tensor.numpy()即可轻松装换由Tensor转换成Numpy
使用paddle.to_tensor(Numpy array(xxx))可以把Numpy转换成Tensor
创建的 Tensor 与原 Numpy array 具有相同的 shape 与 dtype。
| 王小美: |
1 | # 导入numpy |
1 | #dim3_tensor转换成numpy.array |
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipykernel_211/822791399.py in <module>
1 #dim3_tensor转换成numpy.array
----> 2 dim3_tensor.numpy()
NameError: name 'dim3_tensor' is not defined
1 | # 使用Numpy转换成Tensor |
Tensor(shape=[2], dtype=float64, place=Place(gpu:0), stop_gradient=True,
[1., 2.])
| 王小美: |
Tensor报错
Tensor只支持规则的矩阵,对于非规则的会抛出异常!
也就是同一个维度上大小、类型要相同!
平行宇宙的王小美
| 王小美: |
啊呀,三岁老师我的代码报错了,我看不懂你能帮我看看吗?
维数不对会报错!
例如下列代码
rank_2_tensor = paddle.to_tensor([[1.0, 2.0],
[4.0, 5.0, 6.0]])
输出结果
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:345: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify ‘dtype=object’ when creating the ndarray
data = np.array(data)
| 三岁: |

创建一个指定shape的Tensor
Paddle提供了一些API
paddle.zeros([m, n]) # 创建数据全为0,shape为[m, n]的Tensor
paddle.ones([m, n]) # 创建数据全为1,shape为[m, n]的Tensor
paddle.full([m, n], 10) # 创建数据全为10,shape为[m, n]的Tensor
paddle.arrange(start, end, step) # 创建从start到end,步长为step的Tensor
paddle.linspace(start, end, num) # 创建从start到end,元素个数固定为num的Tensor
| 王小美: |
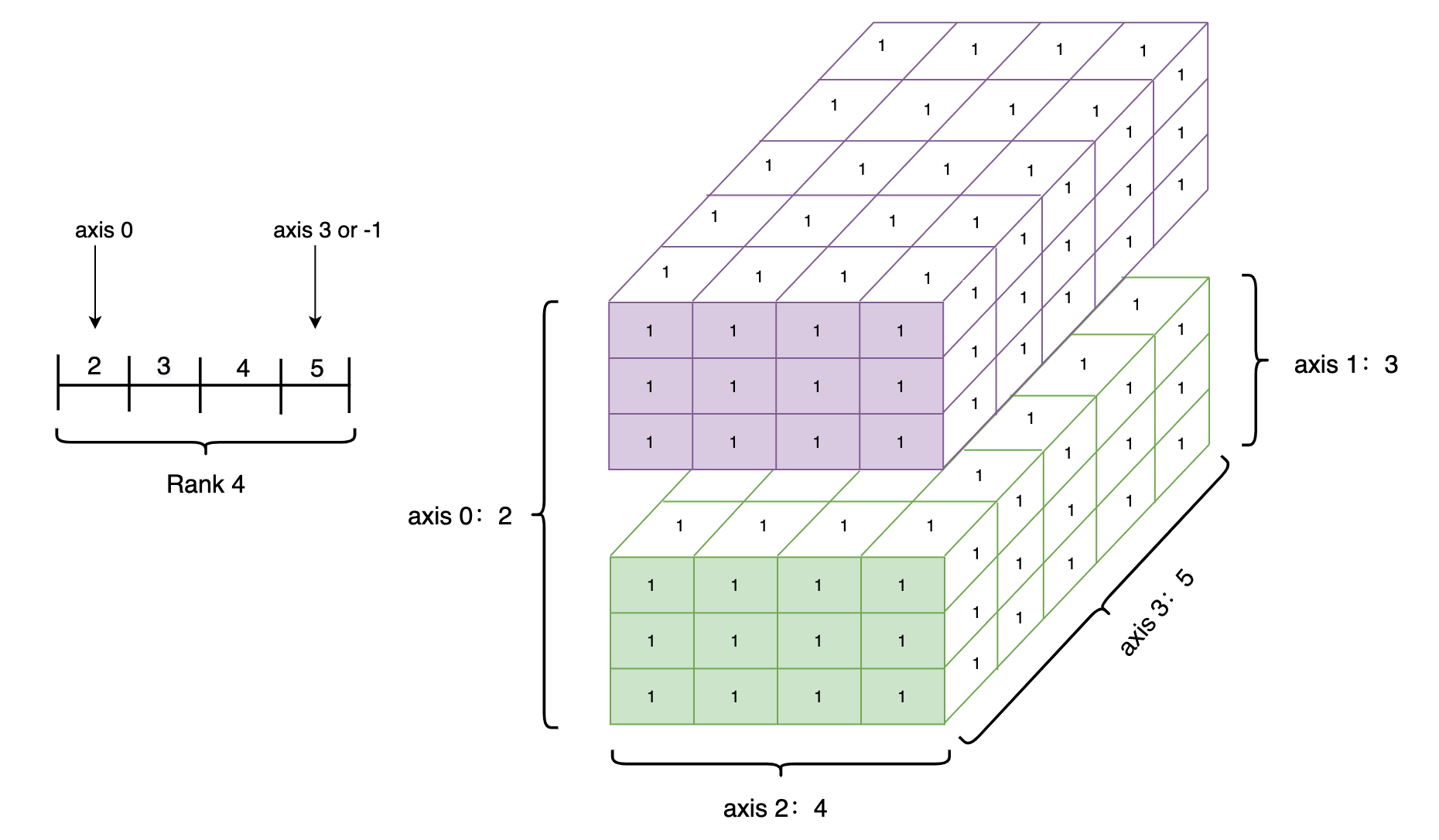
Tensor的shape(形状)
名称 属性 shape tensor的每个维度上的元素数量 rank tensor的维度的数量,例如vector的rank为1,matrix的rank为2. axis/dimension tensor某个特定的维度 size tensor中全部元素的个数
| 王小美: |
| 三岁: |
1 | rank_4_tensor = paddle.ones([2, 3, 4, 5]) |
Tensor(shape=[2, 3, 4, 5], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[[[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]],
[[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]],
[[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]]],
[[[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]],
[[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]],
[[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]]]])
Data Type of every element: paddle.float32
Number of dimensions: 4
Shape of tensor: [2, 3, 4, 5]
Elements number along axis 0 of tensor: 2
Elements number along the last axis of tensor: 5
W0107 17:10:06.180053 179 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0107 17:10:06.184638 179 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
解析结果
Data Type of every element: VarType.FP32
数据类型是32位的
Number of dimensions: 4
维度是4维
Shape of tensor: [2, 3, 4, 5]
大小是[2, 3, 4, 5]
Elements number along axis 0 of tensor: 2
0维度的数量
Elements number along the last axis of tensor: 5
最后一个维度的数量
图解:
| 王小美: |
改变维度
| 王小美: |
| 三岁: |
1 | tensor_x = paddle.arange(0, 4, 1, paddle.float64) |
Tensor(shape=[4, 1], dtype=float64, place=Place(gpu:0), stop_gradient=True,
[[0.],
[1.],
[2.],
[3.]])
| 王小美: |
| 三岁: |
- 0 表示实际的维数是从Tensor的对应维数中复制出来的,因此shape中0的索引值不能超过x的维度。
paddle Tensor的dtype
Tensor的数据类型,可以通过 Tensor.dtype 来查看,dtype支持:’bool’,’float16’,’float32’,’float64’,’uint8’,’int8’,’int16’,’int32’,’int64’。
1 | # 查看tensor_x的类型 |
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipykernel_211/2807053611.py in <module>
1 # 查看tensor_x的类型
----> 2 tensor_x.dtype
NameError: name 'tensor_x' is not defined
dtype类型的指定
通过Python元素创建的Tensor,可以通过dtype来进行指定,如果未指定:
对于python整型数据,则会创建int64型Tensor
对于python浮点型数据,默认会创建float32型Tensor
如果对浮点型默认的类型进行修改可以使用set_default_type进行调整
通过Numpy array创建的Tensor,则与其原来的dtype保持相同
在创建tensor的时候我们就可以通过在后面加类型的方法来指定tensor类型
我们可以看到,王小美同学在改变维度中使用了
tensor_x = paddle.arange(0, 4, 1, paddle.float64)
这样就创建了一个0到4类型为float64的Tensor
Tensor的place
初始化Tensor时可以通过place来指定其分配的设备位置,可支持的设备位置有三种:CPU/GPU/固定内存
其中固定内存也称为不可分页内存或锁页内存,其与GPU之间具有更高的读写效率,并且支持异步传输,这对网络整体性能会有进一步提升,但其缺点是分配空间过多时可能会降低主机系统的性能,因为其减少了用于存储虚拟内存数据的可分页内存。
| 三岁: |
1 | # 创建CPU上的Tensor |
Tensor(shape=[1], dtype=int64, place=Place(cpu), stop_gradient=True,
[1])
1 | # 创建GPU上的Tensor |
Tensor(shape=[1], dtype=int64, place=Place(gpu:0), stop_gradient=True,
[1])
1 | # 创建固定内存上的Tensor |
Tensor(shape=[1], dtype=int64, place=Place(gpu_pinned), stop_gradient=True,
[1])
| 王小美: |

| 三岁: |
| 王小美: |
作者简介
ID:Flose(是不迷失的意思,拖延症有点严重想让自己自律点)
School:浙大宁波理工学院
专业:自动化
深度学习菜狗,正在不断努力,咱们一起加油
后记:
一些好的材料推荐:
跟三岁大佬一起学习(三岁paddle主页)本教程以三岁大佬的教程为基础以对话形式呈现
动手学深度学习对应的paddle版本的电子书推荐这两个配套学习
没有实战但是讲的很易懂吴恩达的机器学习课程
全国大学生智能车竞赛百度完全模型组火爆开赛中!!!
让我们在此相遇